
«Но я лентяй! Я ненавижу работать! Особенно я ненавижу тяжёлый труд во всех его проявлениях! Хитрые и изящные решения — вот мой конёк!»
― Элиезер Юдковский, «Гарри Поттер и методы рационального мышления»
«Торжественно клянусь, что замышляю шалость, и только шалость!»
Что, если я скажу вам, что программирование для современного ученого и инженера — это не просто киллер-фича в резюме, а спасательный трос в мире больших данных, рутинных процессов и нестандартных задач. Именно этой идеи придерживается наше сообщество, одним из ключевых принципов которого является принцип «DIY» (Do it yourself — сделай сам). Идея этого принципа проста: в решении своих повседневных задач мы полагаемся не на монструозные коммерческие костыли в красивой обертке готовые решения, а оптимизируем свои решения с помощью копролитов и палок Python и данных.
Каждый день, от проекта к проекту, мы сталкивается с лавиной данных, которые зачастую невозможно быстро и качественно обработать стандартными инструментами. Готовые программные пакеты хороши для типовых задач, но они бессильны, когда нужно решить что-то нестандартное — будь то автоматическая обработка сотен скважин или поиск скрытых закономерностей в данных. Программирование преодолевает эти ограничения: оно превращает рутину в несколько строк кода, а нестандартные задачи — в вызов, который вы в силах принять.
Цель данной заметки не научить вас программированию, нет. Для этого существует множество отличных источников. Наша цель — дать вам пинок под зад краткое руководство к действию. На примере реальных данных показать, что программирование на Python это максимально просто. Просто настолько, что после прочтения этой заметки даже ваша бабушка пересядет со спиц в Jupyter Notebook.
Если после этого текста у тебя не зачесались руки написать хотя бы строчку кода — проверь пульс. Ты точно ещё жив? Если пульс есть, но желания так и не появилось — сгоняй нам за пивком, а мы пока начинаем.
От таблиц к пространственным данным
Прежде чем мы погрузимся в увлекательный мир программирования, хотелось бы отметить, что при подготовке данной заметки, были использованы геолого-геофизические данные, распространяемые с курсом практических упражнений по сейсмической интерпретации под авторством А.С. Кирилова и К.Е. Закревского. Со своей стороны, SciPunk выражает респект авторам курса за их работу и приверженность принципам свободного распространения обучающих материалов. С деятельностью авторов курса можно ознакомиться на их сайте или сообществе Вконтакте. А теперь стартуем!
Пожалуй одной из самых распространенных форм представления геолого-геофизической информации являются таблицы. С ними мы сталкиваемся постоянно и повсеместно. Таблицы могут храниться как в текстовом (ASCII), так и в бинарном формате.
Начнем с простого: импортируем таблицу со стратиграфическими отбивками из текстового файла формата CSV. Для работы с таблицами в Python есть замечательная библиотека Pandas. Для того, чтобы ей воспользоваться, необходимо для начала ее импортировать:
|
|
Далее, прочитаем содержимое файла TOPs.dat с использованием функции read_csv() из библиотеки Pandas. Для этого нам потребуется всего одна строчка кода. Все что нужно сделать — передать в качестве аргументов в функцию read_csv() несколько параметров:
- Путь до нашего файла
'data\wells\TOPs.dat' - Символ, использующийся в качестве разделителя в фале
csv. В нашем случае это символ пробелаsep = ' ' - Дополнительно используем параметр
skipinitialspace = Trueдля игнорирования лишних пробелов
|
|
Вуаля! Теперь в переменной well_tops хранится объект DataFrame с нашей таблицей стратиграфических отбивок.
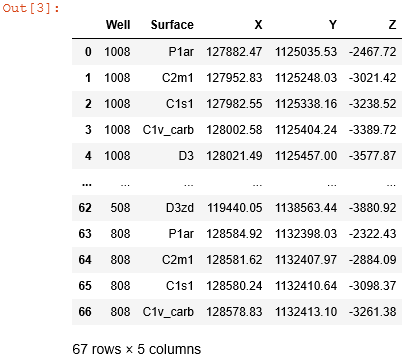
Not Bad! С этим уже можно работать, но мы пойдем дальше. Отличительной особенностью геолого-геофизической информации является ее пространственная привязка. Для тех, кто забыл что это такое, ниже приведена база небольшая информационная справка.
[!info] Геопространственные данные Данные, которые связывают некоторую геологическую информацию с конкретным географическим положением, называются геопространственными, и являются основой геоинформационных систем.
Положение данных в пространстве, может быть представлено двумя системами координат: географической и картографической (прямоугольной). Географическая система координат характеризуется значениями
широтыидолготы. Такие координаты являются неспроецированными и указывают на конкретную точку поверхности Земли. Для того, чтобы отобразить трехмерную Земную поверхность на двумерную плоскость применяются математические преобразования, называемые картографическими проекциями.Картографическая система координат представляет собой спроецированные на плоскость географические координаты
широтыидолготы, и указывает на точку двумерной (картезианской) плоскости изображающую Земную поверхность, c координатамиXиY.Для работы с картографической системой координат важно знать, какая проекция использовалась для отображения пространственных объектов на плоскость. Существует множество различных проекций, каждая из которых подходит под определенные участки Земной поверхности, но ни одна из них не может точно описать всю поверхность, не внося некоторых искажений.
Географическая система координат хороша тем, что указывает конкретное положение на Земной поверхности, но усложняет геопространственные вычисления. Картографическая система координат, наоборот, значительно упрощает геопространственные вычисления, но обладает вышеизложенными недостатками, связанными с невозможностью точного описания всей Земной поверхности одной проекцией.
— Дед, ты бредишь? В таблице же есть столбцы с координатами! — скажете вы мне. — Yep — отвечу вам я.
То, что кажется очевидным для вас, может быть совершенно неочевидным для вашего компутера. Действительно, в нашей таблице присутствуют столбцы с прямоугольными координатами X и Y, но в ней не содержится дополнительной информации о системе координат и проекции.
Для описания геометрии пространственных типов данных в геоинформатике используются геометрические примитивы: точка Point, отрезок LineString, многоугольник Polygon. Примитивы представляют собой набор координат, характеризующих положение этих данных в одной из систем координат. В нашем случае стратиграфические отбивки представляют собой точечные данные, для описания которых подходит геометрический примитив Point.
Теперь давайте модифицируем нашу таблицу так, чтобы она отвечала всем требованиям пространственного типа данных. С этим нам поможет библиотека GeoPandas. По сути это те же яйца, только в профиль тот же Pandas, только с поддержкой всех особенностей пространственных данных. Потребуется еще две строчки кода (хотя можно было бы уложиться и в одну), не считая импорта библиотеки.
|
|
Все что нужно было сделать — это создать специальный объект с описанием геометрии наших данных с помощью функции points_from_xy(), на вход которой мы подали два столбца с координатами well_tops.X и well_tops.Y из нашей исходной таблицы. Затем, на основе нашего DataFrame из переменной well_tops мы создали WunderGeoDataFrame, передав дополнительно переменную с геометрией geometry и информацию о системе координат и проекции crs = 'EPSG:32640' через ее уникальный идентификационный код EPSG. Смотрим что получили:
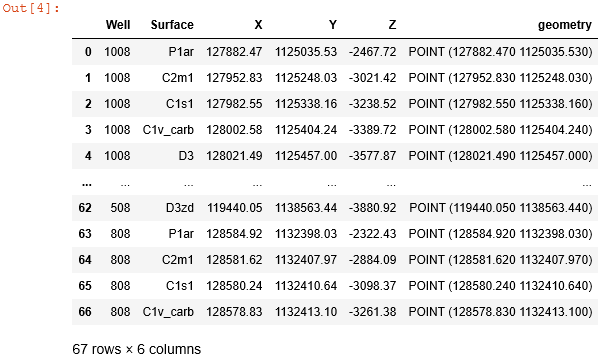
Ничего не напоминает по структуре? Правильно, точечный shp-файл. Теперь столбцы Well, Surface, X, Y, Z — это атрибутивная информация, а geometry — столбец, который хранит геометрию наших точек aka отбивок. А чтобы окончательно вас в этом убедить, давайте сохраним полученный GeoDataFrame в наш первый самопальный shp-файл, вот так:
|
|
Как вы уже могли догадаться, читать shp-файлы с помощью библиотеки GeoPandas не сильно сложнее. Просто передаем путь и имя нашего файла в функцию read_file():
|
|
Теперь посмотрим на данные в таблице. Предположим, нам нужно получить список уникальных значений столбца Surface — легко:
|
|
![]()
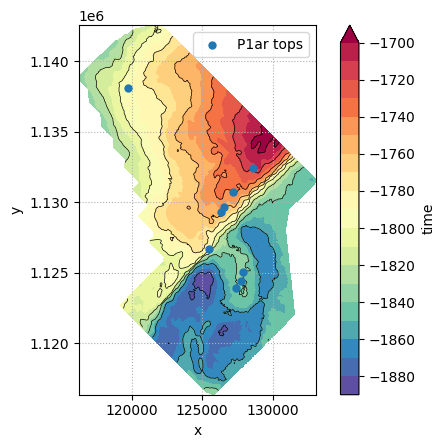
А теперь мы хотим визуализировать отбивки артинского яруса P1ar по всем скважинам. Для начала отфильтруем данные по нашему запросу, а результат сохраним в переменную p1ar_tops:
|
|
Затем, отобразим карту с отбивками используя встроенный метод plot(). При этом маркер отбивки покрасим цветом, согласно значению ее абсолютной отметки column = 'Z':
|
|
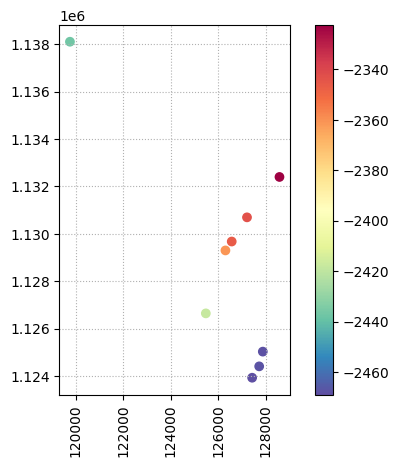
Ваша первая карта, поздравляю! Да, выглядит не очень впечатляюще, но мы только в начале пути, наберитесь терпения. Оставим пока наши отбивки и попробуем подгрузить что-нибудь еще.
Двумерные данные. Поверхности (гриды)
Не одними лишь таблицами живет геолог(иня)\геофизик(чка). Не менее популярный формат представления геолого-геофизической информации — двумерные поверхности (гриды): структурные карты, карты толщин, карты изохрон, матрицы геофизических полей (гравика, магнитка и пр.) и так далее. Их тоже хотелось бы читать из файла. Ну так давайте попробуем. Возьмем один из распространенных открытых форматов Landmark Z-Map Grid. Здесь тоже есть готовые решения, например библиотека Zmapio. Идем по ссылке, читаем документацию, повторяем:
|
|
Чтобы нашим отбивкам не было одиноко, подгрузим поверхность изохрон (времен пробега волны) отражающего горизонта P1ar, полученную по данным сейсморазведки МОГТ-3D. Импортировали — теперь посмотрим на нее, используя встроенный метод plot():
|
|
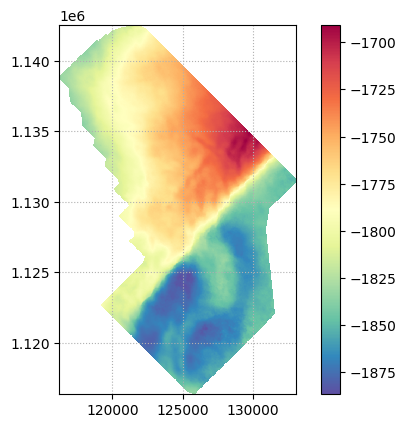
Отлично! Визуализация это конечно здорово, но нам ведь с этими данными еще науку делать работать придется по мере углубления в материал (хотя, откровенно говоря, правильная визуализация данных — уже 70% успеха). Посмотрим, в каком виде zmapio может вернуть нам нашу поверхность. Идем в документацию, смотрим — есть два стула варианта:
Вариант 1: Можно получить двумерный numpy массив используя метод
z_values, вот так:time_grid.z_valuesВариант 2: Работать с поверхностью, как с базой данных, сконвертировав ее в PandasDataFrame, вот так:time_grid.to_dataframe()
В первом случае нам придется обращаться к данным через нумерованные индексы, которые каким-то образом придется постоянно соотносить с координатами. Во втором - работать с плоским массивом данных, но с возможностью поименованного (непосредственно по координатам) обращения к данным. Такая вот вилка в глаз Мортона (или аксиома Эскобара, кому как угодно).
Нам оно не надо. Благо братики постряпали удобную библиотеку Xarray, которая лишит нас этой головной боли. Xarray — это сын маминой подруги в мире многомерных массивов Python. Простыми словами, Xarray — многомерный Pandas, который позволяет работать с массивами, используя поименованные индексы. Не переживайте, если пока не понятно, сейчас будем разбираться.
Итак, для удобства последующей работы создадим двумерный xarray из numpy массива нашей поверхности изохрон, предварительно импортировав необходимую библиотеку:
|
|
Заглянем внутрь полученного массива xarray, вызвав нашу переменную time_grid_xr:

Что имеем? Внутри нашего xarray есть двумерный массив времен пробега волны и два массива с координатами X и Y, используя которые мы можем обращаться к нашим данным. Например, теперь мы легко можем получить значения времен в точках скважин (по их координатам) или снять значения времен вдоль линии сейсмического профиля. Но прежде чем мы это сделаем, давайте отобразим наши данные на одной карте:
|
|
Здесь мы применили чуть более подробное оформление нашего графика:
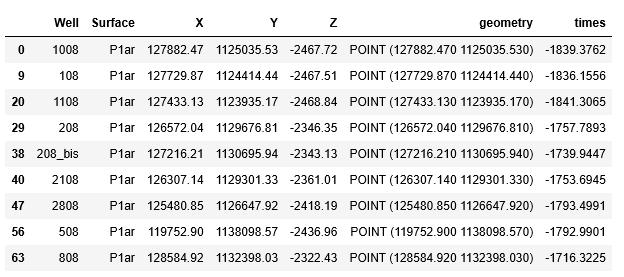
Возвращаемся к нашим индексам. Если бы мы работали с поверхностью как с массивом numpy, мы должны были бы помнить, что “координаты” массива numpy (индексы) всегда начинаются со значения 0 и идут с шагом 1. Предположим: мы хотим получить значения времени пробега волны с карты изохрон в точке скважины с координатой X и Y. Для того, чтобы это сделать, мы должны были бы сначала определить порядковый номер (индекс) этой точки в системе координат numpy массива, и только по этому индексу получить значение с карты. Сложно, согласитесь? Вместо этого мы предусмотрительно сконвертировали наш numpy массив в формат xarray и теперь можем обращаться к данным напрямую по значению координат, а вся головная боль будет происходить под капотом библиотеки xarray. В конце концов мы с вами геологи\геофизики, а не пограмисты за 300кк в наносек — нам и своих проблем хватает. Итак, давайте таки получим значения времен в точках скважин с карты изохрон и запишем их в новую колонку times таблицы с отбивками по артинскому ярусу p1ar_tops:
|
|
Смотрим что получили:
Атлична-атлична! А теперь построим график зависимости “время-глубина” (диаграмма рассеяния aka кросс-плот) в точках скважин, например. Полученные уравнения регрессии братья сейсмики иногда используют для пересчета своих карт времен (изохрон) в карты глубин (структурные карты).
|
|
В этот раз для визуализации графика используем библиотеку Seabron. Это библиотека визуализации красивых статистических графиков, основанная на библиотеке matplotlib.
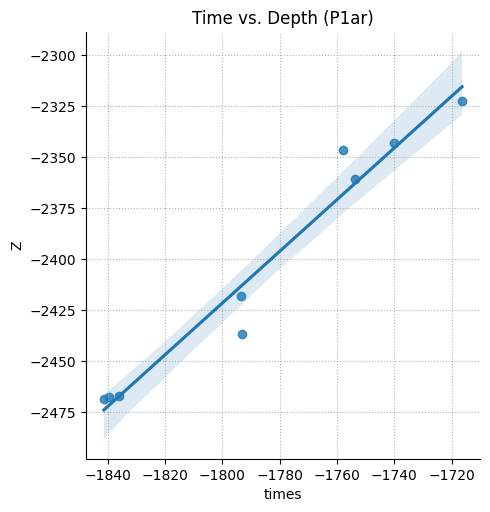
Красивое… Ну что ж, легкой поступью мы с вами подошли к теме анализа данных. Но не будем забегать вперед! Оставим эту тему на следующий урок по DIY. Обязательно научимся оценивать уравнения линейной регрессии, займемся прогнозами (в том числе с помощью машинного обучения) и оценкой неопределенностей. А пока продолжаем разбираться со входными данными.
Данные сейсморазведки. Сейсмические разрезы формата SEG-Y
Карту изохрон мы разобрали, теперь остановимся на данных сейсморазведки, по которым эта карта была построена. Начнем с временных сейсмических разрезов МОГТ-2D. Стандартом хранения сейсмических данных является бинарный формат SEG-Y, разработанный международным обществом геофизиков-разведчиков — Society of Exploration Geophysicists (SEG). При желании, со спецификациями данного формата можно ознакомиться на сайте сообщества.
Благо об этом уже кто-то позаботился за нас, ознакомился со спецификациями к данному типу файлов и любезно предоставил библиотеку для работы с ними. На самом деле таких библиотек на данный момент существует несколько. ObsPy — одна из таких библиотек. Она ориентирована на обработку сейсмологических данных и предоставляет возможность чтения данных в формате SEG-Y. В данном уроке мы воспользуемся возможностями именно этой библиотеки.
[!attention] Как известно, временной сейсмический разрез представляет собой набор так называемых трасс (временных рядов), которые получаются путем суммирования сейсмограмм общей глубинной точки (ОГТ). Поскольку библиотека ObsPy ориентирована, в первую очередь, на работу с данными сейсмологии, то с сейсмическими разрезами она работает именно в контексте временных рядов. Это может показаться не совсем удобно для работы с 2D разрезами и совершенно непригодно для данных 3D, но для понимания структуры формата SEG-Y данная библиотека подходит как нельзя лучше. Более совершенные библиотеки для работы с данными сейсморазведки будут разобраны в следующих
Dungeonmaster-классах
От слов к делу: прочитаем данные SEG-Y файла (временного сейсмического разреза МОГТ-2D). Используем функцию _read_segy из библиотеки ObsPy:
|
|
Функция возвращает нам объект, который содержит в себе 958 трасс, о чем нам любезно сообщает интерпретатор Python: 958 traces in the SEG Y structure. К конкретной трассе можно обратиться по ее индексу (начиная с нулевого). Так и поступим, заодно сразу ее визуализируем:
|
|

Так и есть - трасса. По оси Y здесь амплитуда сигнала, а вот с осью X есть нюанс - вместо привычного двойного времени пробега волны (TWT) здесь отражены дискреты сигнала. Чтобы это исправить, нам нужно получить больше информации о сигнале, как минимум шаг его дискретизации.
— А где его взять?!!11одинодин — спросите вы.
Дополнительная информация о сигнале хранится в заголовках SEG-Y файла, их есть несколько:
- Текстовый заголовок файла:
stream.textual_file_header. Не обязателен к заполнению, нет четкого стандарта его заполнения, а посему часто бывает пустым или содержит нечто бессмысленное - Бинарный заголовок файла:
stream.binary_file_headerимеет четкую структуру и именно там можно найти то, что нас интересует - Кроме того, у каждой трассы есть свой заголовок, доступ к которому можно получить через
stream.traces[0].header. Информация о шаге дискретизации тут тоже присутствует
Теперь давайте пофиксим нашу трассу с учетом вновь полученной информации:
|
|

Теперь все верно. Длина записи сигнала в данном случае составляет 3.6 секунды. Осталось получить разрез целиком. Поскольку ObsPy работает с трассами, то пройдемся по ним в цикле, а результат сохраним в наш любимый xarray:
|
|
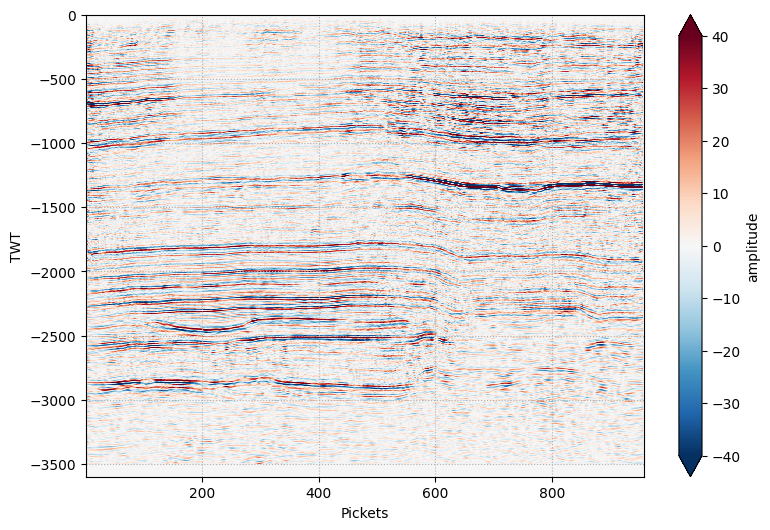
Супер! Осталось разобраться с геометрией профиля. Координаты каждой трассы можно получить через заголовки самих трасс stream.traces[0].header. В нашем случае, координаты были записаны здесь:
X: stream.traces[0].header.source_coordinate_x
Y: stream.traces[0].header.source_coordinate_y
Кстати, никогда не стесняйтесь экспериментировать с кодом: заглядывайте внутрь объектов, смотрите из чего они состоят, обращайтесь к официальной документации и не забывайте яндексить гуглить (лучше всего на английском языке. Так сложилось, что вероятность получить ответ на свой вопрос в англоязычном сегменте интернета гораздо выше).
С местоположением координат внутри файла разобрались. Но не будем же мы считывать координаты каждого профиля по отдельности? Как-никак мы с вами тут про автоматизацию говорили. Говорили? Ну было и было…
Я фантазирую так: как будто мы написали скрипт, который шарится внутри заданной папки в поисках SEG-Y файлов, попутно собирая из них необходимую информацию (включая геометрию профилей), а на выходе выдает нам GeoDataFrame со схемой изученности данными сейсморазведки.
Ох и напифантазировал я на свою голову… Придется отвечать за базар. Ок, дайте мне три дня. Чтобы было проще, разобьем нашу фантазию на подфантазии:
- Написать функцию, которая будет осуществлять поиск файлов с заданным расширением файлов внутри заданной папки, а на выходе выдавать нам
DataFrameс находками - Написать функцию, которая будет последовательно проходить по списку найденных SEG-Y файлов из
DataFrame, считывать из них необходимую информацию, а на выходе формироватьGeoDataFrameс геометрией сейсмических профилей
Звучит неплохо. Давайте начнем с первого пункта:
|
|
Итак, мы написали функцию scan_files, которая реализует функционал из первой подзадачи (см. выше). Функция ожидает на вход два аргумента:
- Путь в формате строки, где необходимо искать файлы —
path - Тип файлов в формате кортежа Pyhton, которые мы собираемся искать
Функция осуществляет рекурсивный поиск файлов заданного типа (включая вложенные каталоги) и возвращает DataFrame с найденными файлами. Проверим: вызовем нашу функцию, передав необходимые аргументы, а результат сохраним в переменную sgy_files
|
|
Отлично! Теперь мы можем использовать цикл для перебора содержимого полученного DataFrame, и считать необходимую информацию из найденных файлов SEG-Y:
|
|
FUCK YEAH! Кажется у нас получилось. Конечно, я немного схалтурил и не стал оформлять код в функцию, а еще не вынул дополнительную важную информацию из заголовков, но моя основная задача заключалась в том, чтобы научить вас ловить рыбу, а не накормить ей. Think about it… Зато я добавил исключения try — except, чтобы скрипт не спотыкался на кривых SEG-Yях. В качестве домашнего задания оставляю вам доработку напильником данного скрипта с учетом вышесказанного и ваших смелых идей. Результаты домашки будем рады видеть в нашем telegram-канале, в комментариях под новостью о статье.
Кстати, GeoDataFrame с положением сейсмических профилей seismic_gdf можете сохранить в shp-файл, как мы делали это с отбивками (см. выше) и загрузить его в ваш ArcGIS QGIS проект.
А теперь предлагаю нанести все наши данные на одну обзорную схему:
|
|
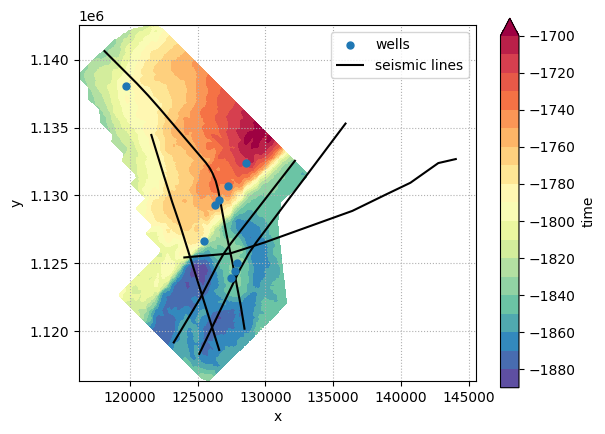
Ну и пожалуй последнее, что мы сделаем сегодня — снимем значения времен с карты изохрон вдоль какого-нибудь сейсмического профиля, для того, чтобы нанести их на сейсмический разрез. Решить данную задачу можно по аналогии с тем, как мы делали это для скважин:
|
|
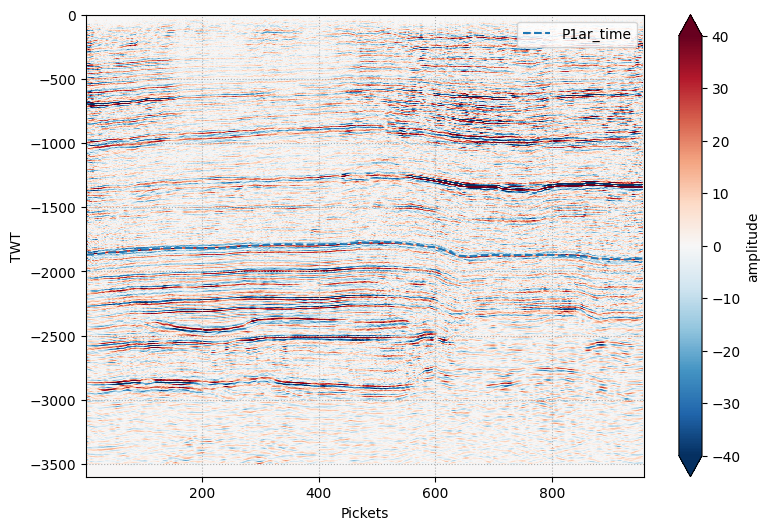
Заключение
На сегодня все. Подведем итоги. Сегодня мы:
- Научились читать табличные данные из файла CSV-формата c помощью Python и библиотеки Pandas
- Вспомнили базу из геоинформатики и поговорили о геопространственных данных
- Научились превращать скучные таблицы в пространственные с помощью библиотеки GeoPandas
- Создали свой первый shp-файл
- Загрузили свой первый shp-файл
- Научились работать с поверхностями формата Z-Map
- Познакомились с библиотекой Xarray, разобрались почему этот формат хорош для работы с гридами
- Научились извлекать информацию из грида используя координаты
- Вплотную подошли к основам анализа данных — линейной регрессии. Договорились вернуться к ней позже
- Разобрались как устроен формат SEG-Y. Научились работать с сейсмическими разрезами с помощью библиотеки ObsPy
- Автоматизировали нашу первую рутинную задачу — написали шныря по папкам, который умеет строить схему изученности данными сейсморазведки МОГТ-2D. Да, он все еще не идеален, так что не забываем про домашнее задание.
Основную цель, которую мы преследовали при подготовке вводного урока по «DIY» — показать, что навыки программирования сегодня являются своего рода суперсилой для современного ученого и инженера, а также дать заинтересованным хорошую отправную точку для экспериментов со своими данными и подготовить читателя к нашей постоянной рубрике «очумелые ручки».
Безусловно, не весь спектр данных был освещен в данной заметке. В следующих уроках мы обязательно разберемся с данными сейсморазведки МОГТ-3D и поговорим про работу с данными геофизических исследований в скважинах (ГИС).
NB: Если вы до сих пор тратите часы на монотонные клики в интерфейсе, значит, вы уже отстаёте. Пора брать контроль над данными в свои руки — и Python ваш лучший инструмент для этого. Не забывайте: в эпоху big data и искусственного «интеллекта» выживут только те, кто умеет говорить на языке машин.
«Шалость удалась!»